Arama Motorları Nasıl Çalışır?
Neredeyse hepimiz her gün, hatta günde yüzlerce kez Google'a gireriz. Ya da Yahoo, Bing, Yandex... Bu sitelerin hepsi "arama motoru" olarak tanımlanan sitelerdir. Özellikli bir bilgiyi, siteyi, görseli veya daha birçok veriyi arama motoru aracılığıyla bulabiliriz ve bu işlem koskoca Web'te, 1 saniyeden kısa bir zamanda tamamlanıp, önümüze sunulur. Özellikle vurgulamak gerekir ki, koskoca Web... Ve aradığınız belki de yalnızca "bir" kelime. İşte bu ay sizlere, bu harika teknolojinin nasıl işlediğini anlatacağım.
Arama motorlarının kendilerine has çalışma metodları olmasına rağmen, temel olarak şu 3 prensibe göre işlerler:
- Anahtar kelimelere bağlı olarak, interneti ararlar/ internetin olası bölümlerini seçerler.
- Bulunan kelimelerin ve bulunduğu yerlerin olduğu bir dizin tutarlar.
- Kullanıcılara, doğru kombinasyonu seçmeleri için kelimelerin bulunduğu yerleri görüntülemeye izin verirler.
Anahtar kelime 3 farklı yol ile bulunabilir. Spider (veya Ant) adı verilen özel yazılım robotları, insanlar tarafından sunuluş ve bu iki sistemin hibriti olan başka bir sistem.
Spider adı verilen özel yazılım robotları, bu kelimeleri bulur ve bulundukları yerlerin olduğu dizini oluşturmaya başlar. Bu dizin oluşum aşamasına Web Crawling adı verilir. Spider öncelikli olarak, yoğun kullanılmakta olan serverlara ve popüler sayfalara göz atar. Kelimeler, sitelerin HTML veri tabanlarından elde edilir. Crawler bu sırada, arama motoru yöneticisi tarafından belirlenmiş bir periyotla, bulunan adreslerde bir değişiklik olup olmadığı durumunu kontrol etmek amacıyla, adresleri tekrar kontrol eder.
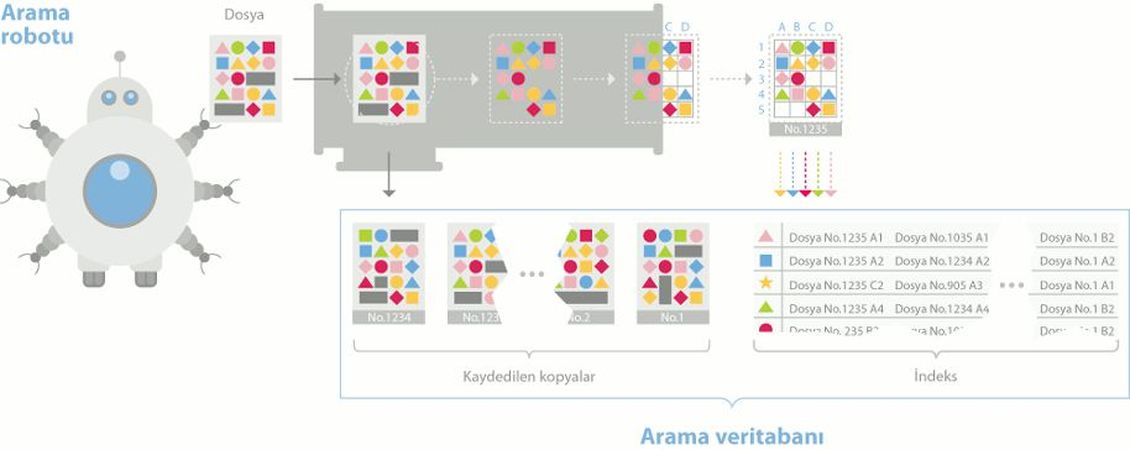
İnsanlar tarafından sunulmuş olan yolda ise, yalnızca insanlar tarafından dizinlenmiş veya kataloğa eklenmiş verilere erişilebilir.
Bu adımdan sonra, iki durumda da asıl Web yerine, oluşturulmuş dizin üzerinde arama yapılır. İndeks güncellenmediği zaman ise, bilginin hala o adreste yer almasa bile, adres dizinde kalır ki bu da arama sonuçlarının kalitesini düşüren bir faktördür.
İndeks oluşturma aşamasında ise, göz önünde bulundurulması gereken 2 ana konu vardır:
- Veri ile birlikte kaydedilen bilginin içeriği
- Bilginin dizinlenme metodu.
En basit şekilde veri ile URL'yi dizinde tutmanın yeterli olabileceğini düşünebiliriz. Fakat, kelimenin o adreste kaç kez tekrarlandığı da, aramanın kalitesi açısından önemli bir detaydır. Bu yüzden kelimenin tekrar edilme sayısına göre, daha uygun çözümler, daha ön sıralara gelmelidir. Ayrıca bulunan sayfaların ne kadar fazla sayıda bir başka sayfayla bağlantılı olduğu bilgisi de aramanın kalitesini arttıracaktır. Örneğin Google, ranking(başarı sırası) için Web sayfasının kalitesini, güncelliğini, güvenli içerik oluşunu, web geçmişi veya coğrafi konum gibi kullanıcı özelliklerini, dil ve ülkeyi ve ilgili diğer (harita, haber, video gibi) dökümanlarla olan bağlantısını göz önünde bulundurur.
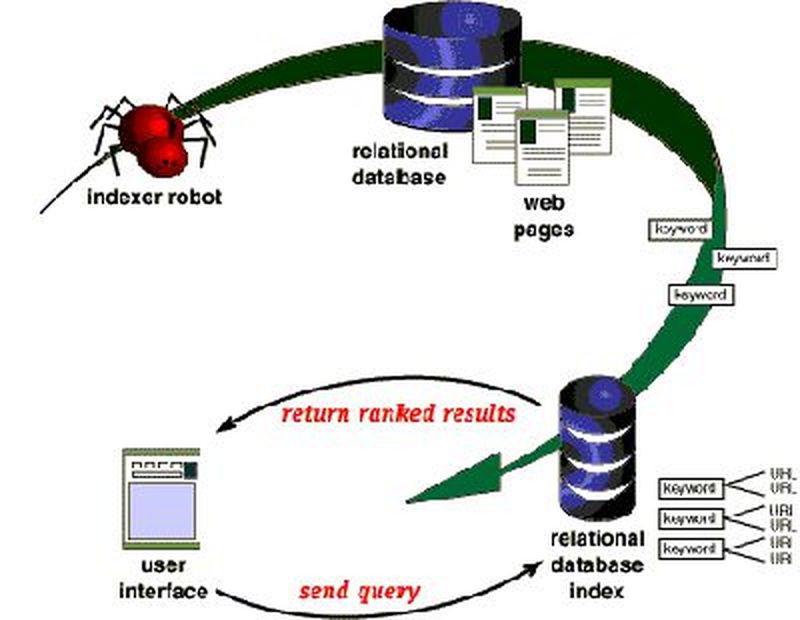
İndekslemenin amacı, aranılan bilginin kolay bir şekilde bulunabilmesidir. Bu yapılırken, en çok tercih edilen yol ise bir hash table(komut tablosu) oluşturmaktır. Tablo oluşturulurken her kelimeye bir sayı değeri ataması yapılır. Bu sayı ataması yapılırken, alfabetik sıra yerine, hangi harfte daha çok kelime olduğu bilgisi göz önüne alınır.
Bunun dışında milyarlarca sayfa için varolan hafıza alanı limitsiz gibi değerlendirilebileceğinden, bu bilgi yeniden kodlanarak, daha az yer kaplayacak bir seviyeye getirilmelidir.
İndeks hazırlandıktan sonra, arama motoru aracılığıyla, kullanıcının sorgulama yapması için seçeneklerin sunulması ile sonlanır.
Spam olarak değerlendirilebilecek sonuçlar otomatik olarak sonuç dışı edilir. Ancak kesin olmayan sonuçlar için manuel değerlendirme yapan arama motorları bulunmaktadır.
Arama motorlarının birbirinden farklı kalitede sonuçlar vermesinin nedeni kullanılan algoritmalardır. Bu algoritmaların ne kadar verimli olduğu konusunda araştırmalar yapıldıkça arama sonuçları daha kaliteli hale gelmektedir.
Kaynaklar: