Okumakta olduğunuz bu yazı alana özgü bir yöntem olduğu için bu konuda zaten bilgisi olan okuyucularımıza yöneliktir.
Günümüzde gittikçe önem kazanan yapay zeka algoritmalarından birisi olan yapay sinir ağları (artificial neural networks – ANN) eğitim (training) süreci için yüksek miktarda depolama alanına ve işlem gücüne gerek duyuyor . Yüksek başarımlı sinir ağları oluşturmak için yüksek bir nöron sayısı ve geniş veri kümeleri gerekebilir.Bu durum da ANN programlarının geliştirilme sürecinin uzamasına ve maliyetli bir hale gelmesine yol açıyor. Bunun yanı sıra taşınabilir teklonojilerde de kendine yer bulmaya başlayan ANN sistemleri de ele alındığında ileride ele alacağımız pruning metodunun önemi daha iyi anlaşılıyor
Bu yazıda durumu iyileştirmek için kullanabileceğimiz yöntemlerden birisi olan “pruning” yöntemini inceleyeceğiz.Öncelikle durumu anlamak için ANN‘lerin matrix uygulamasında gözlenen durumlardan biri olan sparsity durumunu inceleyeceğiz.
Sparse Matrixler (Aralıklı Matrix)
Bilgisayarlardaki pruningden önce memeli beynindeki pruningi tanıyalım . Görüldüğü gibi ANN algoritmasının çıkışı kaynağı gibi burada tanıtacağımız olay da biyoloji kaynaklı . Embriyonik gelişimle beraber bireyin beyni nöron sayısı ve sinaps miktarı bakımından büyür . Doğuma yakın bir zamandan başlayarak ise nöronlardaki akson ve dentritler ölmeye başlar böylece insan beyni şekillenmiş olur ve bu durum öğrenme ile ilişkilendirilir .

Günümüzdeki nöral ağlar amaca yönelik olarak milyara ulaşacak sayıda bağlantı içerebiliyor [4].Bu bağlantılar bilgisayar sistemlerinde matrixler ve bunlarla yapılan matematiksel işlemler olarak ifade edilir . Ancak nöral ağları oluşturan matrixler kurulum (initilization) sürecinde ve gelişim sırasında sparse matrixlere dönüşebilir . Sparse matrix ise kısaca elemanlarının çoğunluğu 0 olan matrixlerdir ancak biz bu yazıda ve pruning çerçevesinde sıfıra çok yakın değerleri de 0 gibi ele alacağız [4].
Pruning (Budama)
Sparse matrix kavramını tanıttığımıza göre pruning işlemi ve bunun arkasında teoriyi sunmadan önce durumu inceleyelim.
- Nöral ağı oluşturan matrixlerin içinde değeri sıfıra yakın parameterler var.
- Söz konusu parametreler çarpımlarda sıfır ürettikleri için sonuca pek etki etmiyorlar.
- Sonuca etki etmedikleri gibi sistemde yer kaplayıp işlem maliyetini yükseltiyorlar.
O zaman biz bunları matrixlerden eksiltirsek işlem gücünden ve veri alanından tasarruf edip aynı ağın pruninge uğramamış haline yakın sonuçlar elde edebiliriz.
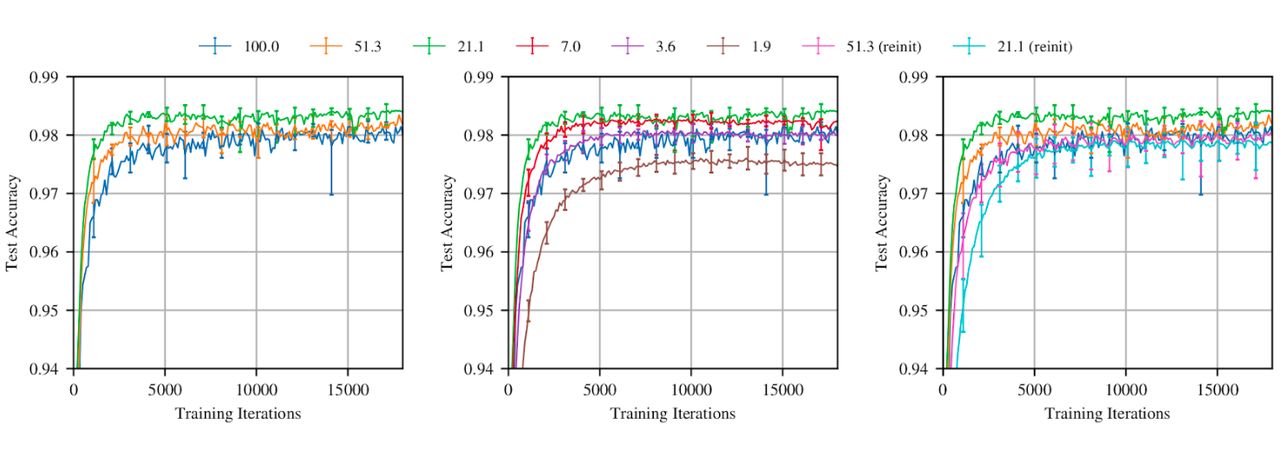
Yapılan bu teste görüldüğü gibi programın eğitim sürecinde , başlangıçta olan parametrelerin sadece yaklaşık %21 kullanılarak hiç pruning yapılmamış haline yakın hatta daha yüksek bir test başarı yüzdesi elde ediliyor (Yeşil ve mavi çizgiler).[5]
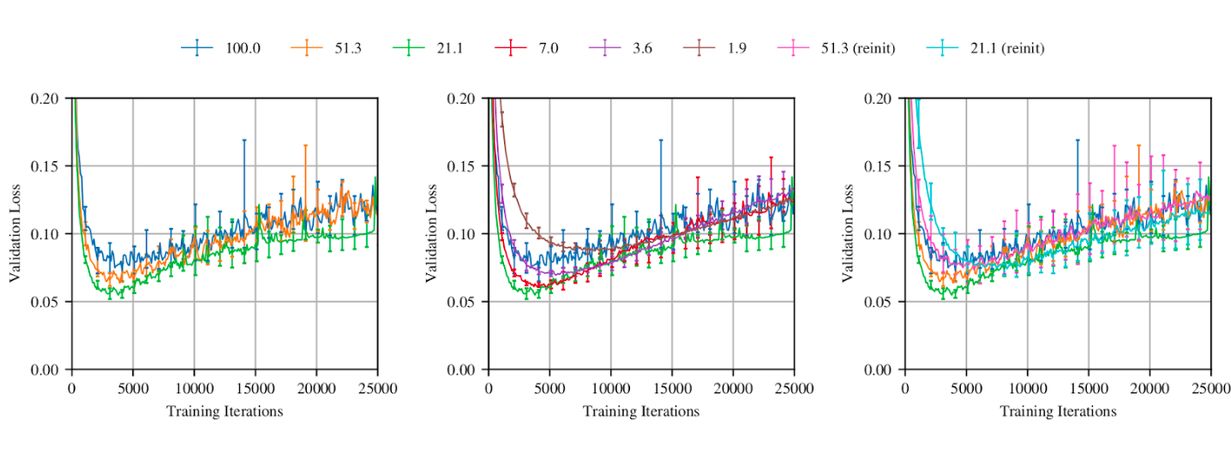
Burada da aynı sistemin hata yüzdelerini görüyoruz. Parametrelerin yaklaşık %21‘i kalana kadar pruning uygulanmış program diğer durumların çoğundan daha düşük bir hata oranına sahip. Pruning yüzdesi daha da düştükçe programın başarımının azaldığını ve hata oranın yükseldiğini görüyoruz. [5]
Sonuç olarak pruning yönteminin ağın başarımına olumlu etki ettiğini söyleyebiliriz. Ancak burada bahsedilmesi gereken başka bir durum ise birtakım parametreleri eksiltmek için harcanabilecek çoklukta parametreye yani noröna gerek duyulabiliyor . Bu yüzden pruning yönteminin “underfitting” tehlikesiyle burun buruna ağlarda pek kullanışlı olmayacağı söylenebilir.
Pruning yöntemini inledeğimiz bu yazıyı burada sonlandırıyoruz .Aslında bu konuda söylenecek daha çok söz var zira ANN geniş bir araştırma alanı . Merakını gidermek isteyen arkadaşları ileri okumalara yönlendiriyorum .
Bir sonraki yazılarda görüşmek üzere .
İleri Okumalar :
1. Kaynakça.
2. https://towardsdatascience.com/pruning-neural-networks-1bb3ab5791f9
Kaynakça:
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł.,andPolosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805.
Child, R., Gray, S., Radford, A., and Sutskever, I. (2019). Generating long sequences with sparse transformers. CoRR, abs/1904.10509.
Dettmers, Tim, and Luke Zettlemoyer. “Sparse Networks from Scratch: Faster Training without Losing Performance.” ArXiv.org, 23 Aug.2019 , https://arxiv.org/abs/1907.04840.
Frankle, J.,Carbin ,M. (2018, March 9). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. ArXiv.Org. https://arxiv.org/abs/1803.03635
(“Synaptic Pruning”,Wikipedia, Wikimedia Foundation , 26.11.2021 , https://en.wikipedia.org/wiki/Synaptic_pruning).