Şubat sayımızda, algoritma konusuna giriş yapmış, Mart sayımızda da, "sıralama algoritmaları"yla detaya inmeye başlamıştık. Şimdi sıra Arama Algoritmalarında(searching algorithms).
Arama algoritmaları da, sıralama algoritmaları gibi, bilgisayar biliminde sıkça kullanılan algoritmalardandır. Hızı, bellek kullanımı, yazım kolaylığı konularında farklılık gösteren algoritmalar mevcuttur. Arama algoritmalarını kullanmamızdaki amaç, -algoritmanın isminden de anlaşılacağı üzere- aradığımız veriye en kısa yoldan ulaşmamızı sağlayacak bir yöntem bulmaktır. Bu yazımızda, en popüler arama algoritmalarını anlatmaya çalışacağım.
Sırayla Arama (Sequential Search)
Veri setini, bastan sona kadar, teker teker kontrol ederek, aradığımız veriye ulaşmaya çalıştığımız arama algoritmasıdır. Setimiz ne kadar büyükse, programımızın çalışması o kadar uzun sürer.
İkili Arama (Binary Search)
Bu algoritma, sıralanmış setler için geçerli bir algoritmadır. Bu algoritmada yapılan işler kısaca şöyledir:
Veri setinin ortasındaki sayıya bakılır. Aradığımız sayı, bu sayıdan buyukse, ortadaki ve sondaki veri seti, yeni veri setimizmiş gibi davranılarak, tekrar bu setin ortasındaki sayıya bakılır. Örnekle açıklayalım:
0-1-2-3-4-5-6-7-8-9 ---> veri setimiz olsun. Aradığımız sayı da 8 olsun. Setimiz 10 elemanlı.Ortadaki veri 5. sıradaki (10 / 2 = 5). 5. verimiz ise 4, bizim aradığımız sayıdan küçük. Bu durumda, 5. ve sonuncu kısmı yeni veri setimiz olarak alıyoruz.
5-6-7-8-9 ----------------> yeni veri setimiz 5 elemanlı. Ortadaki veri 7. Bu da 8 den küçük.
Yine aynı işlemi yapıyoruz.
8-9 ---------------------> yeni veri setimiz 2 elemanlı. Ortadaki veri 8.
Gördüğünüz gibi, sırayla bakarak 8. seferde bulabileceğimiz veriyi, ikili aramayla 3 seferde bulduk.
Enine Arama (Breadth-first search (BFS))
Enine arama aslında bir grafik algoritmasıdır. Ağaç yapılarında kullanılır. Bu arama algoritmasını size basit bir şekilde anlatmaya çalışacağım. Resimde gördüğünüz yapı, "ağaç"(tree) olarak adlandırılır. Programlamada kullanılan yapı türlerinden biridir. Her bağlantı noktasında veriler saklanır. Veriler de birbirleriyle ilişkilendirilir.
BFS’teki arama sırasını, bağlantı noktalarında görünen rakamlardan takip edebiliriz. Adından da anlaşılabileceği gibi, ağaç yapısını, yukarıdan başlayarak, soldan sağa tarayarak ilerler.
Boyuna Arama (Depth-first search (DFS))
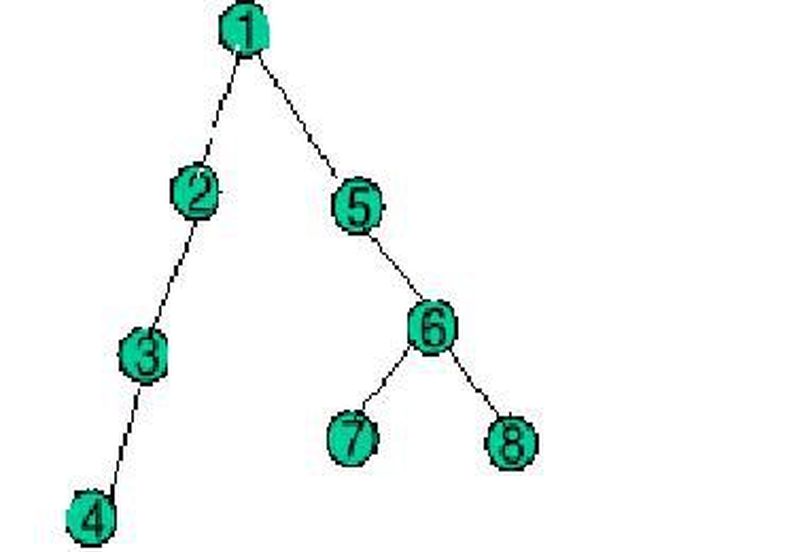
Boyuna arama da, enine arama gibi, grafik algoritmalarındandır. Ağaç yapılarında kullanılır. Arama işlemine, BFS gibi en üstteki bağlantı noktasından –kök (root)- başlanır, ama BFS'nin aksine, yatay değil de dikey olarak ilerler. Kökten itibaren, en soldan gidebildiği en alttaki baglantı noktasına kadar iner, en alttakine ulaştıktan sonra, daha yukarıdaki bağlantı noktalarına aynı işlemi uygular. Yandaki resimde yine örneğini görebilirsiniz.
DFS algoritması, bağlantı noktalarında yazan rakamlar doğrultusunda arama yapar. Aynı şekilde, mesela ağaç yapımız, BFS'teki gibi olsaydı, arama şu şekilde olacaktı:
1 – 2 – 5 – 9 – 10 – 6 – 3 – 4 – 7 – 11 – 12 – 8
Aradeğerleme Arama (interpolation search)
Bu arama algoritması, mantık olarak, ikili aramaya çok benzer. Fakat bu algoritmada, veri setinin ortasındaki elemana bakmak yerine, tahmini bir yer bakarız (tahminimizin olması için de küçük bir hesap yaparız tabi ki). Bunu sözlükte kelime aramaya benzetebiliriz. Mesela “maymun“ kelimesini aramak için ilk yapacağımız iş, sözlüğün ortalarına yakın bir sayfayı rastgele açmak olacaktır. Açtığımız sayfadaki kelimeler “i” harfi ile başlıyorsa, birkaç sayfa daha ilerideki bir sayfayı açarız, ama “m” harfindeysek birer ikişer ilerleyerek yeni sayfalara bakarız.
Bu algoritmayı kullanabilmemiz için, sahip olduğumuz setteki verilerin kaç çeşit olabileceğini bilmemiz gerekiyor. Mesela harflerden oluşan bir set içerisinde bir arama yapacaksak, Türk alfabesi için 29 farklı veri olabileceğini biliyoruz. Bir de, tahmini bir sıradan bahsetmiştik. O sırayı bulmamız için bir formül kullanıyoruz:
Bakacağımız sıra = ilk verinin setteki yeri + [(aradığımız verinin alfabedeki yeri – ilk verinin alfabedeki yeri ) / (son verinin alfabedeki yeri – ilk verinin alfabedeki yeri)] x (son verinin setteki yeri - ilk verinin setteki yeri)
Formül biraz karışık görünse de aslında kolay. Şimdi bu algoritmayı bir örnekle daha anlaşılır hale getirelim:
Veri setimiz:
A A A C E E E G H I L M N P R S X olsun. İngiliz alfabesini kullanıyoruz. Toplam 17 verimiz var. Aradığımız harf de M olsun.
- M harfi, alfabede 13. sırada.
- X harfi listede 17. sırada, alfabede 24. sırada.
- A harfi listede ve alfabede 1. sırada.
Bakacağımız sıra, x olsun.
X = 1 + [ (( 13 - 1 ) / (24 – 1)) x ( 17 - 1) ] = 9.3
9. verimiz: H harfi, bizim aradığımız harf değil. Aynı arama işini listenin geri kalanıyla tekrar yapıyoruz:
Yeni setimiz : I L M N P R S X.
I alfabenin 9. harfi, setimizde 10. sırada.
X = 10 + [ ((13 - 9) / ( 24 - 9 )) x (17 - 10) ] = 11.86
11. verimiz: L harfi, bizim aradığımız harf değil. Aynı arama işini listenin geri kalanıyla tekrar yapıyoruz:
Yeni setimiz : M N P R S X
X = 12 + [ ((13 - 13) / ( 24 - 13 )) x (17 - 12) ] = 12
12. verimiz ise M harfi, yani aradığımız harf.
Bu algoritmayı, anlatması kadar uygulaması da zordur. O yüzden, eğer çok büyük verilerle uğraşılıyorsa ve algoritmanın hızı çok önemliyse, bu algoritma kullanılabilir.
En yaygın olan arama algoritmalarını sizlere anlatmaya çalıştım. Diğer algoritmalar gibi, uygulayacağımız algoritmayı seçerken, kullanacağımız veri yapılarını, verilerin büyüklüğünü, hızın ve performansın önemini göz önünde bulundurmalıyız.