Merhabalar, bergimizin bu ayki sayısında sizlere ses tanımadan bahsedeceğim. Ses tanıma teknolojileri, bilindiği gibi giderek önemli bir unsur olmaya devam ediyor. Bu sayede hayatın ne derece kolaylaştığı, zamandan tasarruf etmenin hayati öneminin arttığı günümüzde iyice gözler önüne seriliyor. Öncelikle bu teknolojinin tarihinden kısaca bahsetmek istiyorum.
Ses tanıma teknolojisinin kökeni 18. yüzyılın ikinci yarısına rastlıyor. O sıralarda konuşmayı yazıya çevirmekten çok “konuşan” makineler yapılmaya çalışılmış. 1773'te Rus bilim adamı Kratzenstein, kilisi orglarının boruları ve rezonans tüplerini bağlayarak sesli harfler çıkarmayı başarmış. Ardından Viyanalı von Kempelen, Akustik-Mekanik Ses Makinesi icat etmiş. Ses tanıma adına daha büyük adımlar 20. yüzyılda, birçok teknolojinin doğduğu Bell Laboratuvarları'nda atılmış. Homer Dudley ve Harvey Fletcher konuşmada çıkan sesi tanımlamada sinyal aralığının önemli olduğunu bulmuşlar. Modern ses tanıma algoritmalarının temeli de onların yöntemlerine dayanıyor. 1962'de yine Bell Laboratuvarları'nda yalıtılmış sözcük tanıma yapılıyor. Bu noktadan sonra kademeli olarak ses tanıma kapasitesi daha çok ve daha karmaşık söz dizimlerini çözümlemeye kadar gidiyor.
Tüm bu gelişmeler üzerine yapılanan ses tanıma işleminin temel taşlarından olan matematiksel yapıların birkaçından bahsedeceğim.
Saklı Markov Modeli
Eğer Biçimsel Diller ve Soyut Makineler (Formal Languages and Abstract Machines) dersini aldıysanız, şimdi bahsedeceklerimi daha iyi anlayabilirsiniz (Başvuru için: http://en.wikipedia.org/wiki/Finite_State_Machines). Ses tanıma sistemlerinde, ses dalgaları öncelikle ses vektörleri veya gözlemleri dizilerine dönüştürülürler. Bu diziler, Markov özelliğinde bir sonlu-durum makinesi olarak ele alınırlar. Öyle ki, gözlem dizilerinde bir sonraki gözlem, geçmişteki herhangi bir gözleme değil, şu ankine bağlıdır. Fakat gerçekte bu sistemin bazı sınırlamaları vardır: modeldeki durum dizisi saklıdır ve gözlemler sadece bu durumlara bakılarak hesaplanır. Buna Saklı Markov Modeli denir. Ses sinyalleri simgeselleştirilerek sonlu-durum makineleri olarak işlenirler. Tabi biçimsel diller düzeyine çıkarılmadan önce, pek çok ses dalgası hesaplamaları yapılır. Bu tür hesaplamalar ise sinyal işleme konusuna girdiğinden onlardan söz etmeyeceğim.
Saklı Markov Modelindeki durum dizisini bulabilmek için üç önemli algoritma kullanılıyor. İleri Algoritması: Modeldeki durumların sırasını bulmada kullanılıyor. Ortaya çıkabilecek tüm durum sıralarının olasılıkları toplanıyor. Viterbi Algoritması: İleri Algoritması'ndaki gibi tüm olasılıkları toplamak yerine, Viterbi algoritmasında her durum sıralarından ses vektörleriyle en iyi örtüşeni seçiliyor. Böylece daha sağlıklı bir sonuç elde ediliyor. Baum-Welch Algoritması: Gözlem dizisini baştan sona ve tekrar sondan başa geçerek gözlem olasılıklarını hesaplar. Böylece daha kesin sonuçlar bulur.
Ses sinyallerini işleyip, en küçük parçalarına ayırdıktan sonra, bu parçaların denk geldikleri ses ve hecelerle örtüştürülmesi gerekiyor. Bunun için tanımak istediğiniz ifadeleri türeten gramerden, telaffuz sözlüğü, sözcük ağları, gibi pek çok öğeyi harmanlamak gerekiyor.
Ses Tanıma Nasıl Yapılır?
Öncelikle vereceğiniz sınırlı sayıdaki komutu türetebileceğiniz bir biçimsel diliniz olması gerekiyor. Herhangi bir ses tanıma araç takımı kullandığınızı varsayalım. Bu dilin gramerini, söz gelimi Bachus-Naur formatında tasarladıktan sonra, kullandığınız yazılımla grameri işleyerek olası tüm sözcük dizilimlerini gösteren bir sözcük ağı kuruyorsunuz. Daha sonra kullanacağınız sözcükleri listeleyerek, bu sözcükleri hangi dilde ses tanıma yapacaksanız, o dilin telaffuz sözlüğüyle birleştirmeniz, her sözcüğün ne kadar telaffuzu, fonemi varsa eşleştirmeniz gerekiyor. Sözcüklerin arasında bıraktığınız boşluğa kadar, tek tek tüm fonemlerin telaffuzunu elde etmiş oluyorsunuz.
Bir sonraki aşamada ise vereceğiniz olası tüm komutları kendi sesinizle kaydediyorsunuz. Bu nokta önemli, çünkü makine ilk başta yalnız bir kişinin sesini tanımak üzere eğitilir daha sonra diğer seslerle uyarlaması yapılır. Ayrıca tüm örnek komutların her birini mümkün olduğunca birden fazla kaydederek, sesinizin metinle örtüşme olasılığını da artırmış oluyorsunuz. Çünkü ses her zaman her sözcük için aynı dalga boyunda olmayabilir. Üstelik ses kaydetme anında arkadan gelen sesler de ses tanımayı önemli ölçüde etkiler.
Ses kayıt işleminden sonra kullandığınız araç takımının gerektirmesine bağlı olarak ses dosyalarını etiketlersiniz. Her dalga boyunun hangi sözcüğe ait olduğunu başka türlü belirlemeniz mümkün değildir. Etiketleme işlemi çok önemlidir, çünkü dalgaboylarının sınırları iyi belirtilmezse sesin gerçek analizi yapılamamış olur.
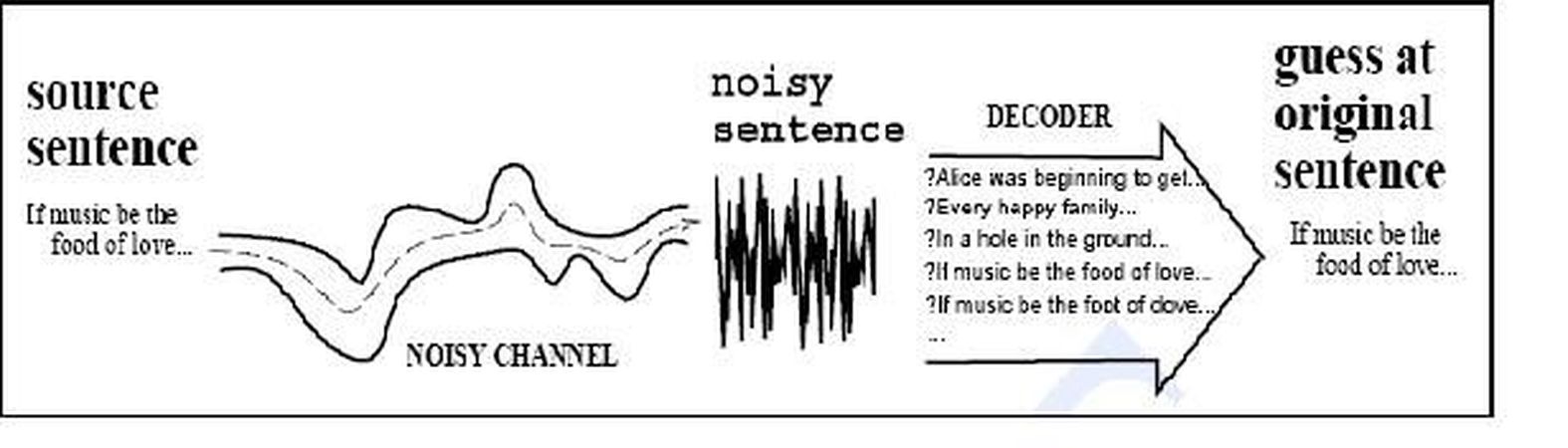
Bu adımdan sonra da ses sinyalleri _Mel frekansı sepstral katsayıları_na bölünürler. Sinyal işleme ile ilgili birtakım hesaplamalar yapılır. Sinyallerin bölümünden sonra ise yukarıda bahsettiğim algoritmalar kullanılarak bir dizi istatistiksel işlemle etiketlenen ses dalgaları sözcükler ve fonemlerle birleştirilir. Tüm işlemler doğru şekilde yapılırsa, ses tanıma araç takımının sağladığı ara yüzle sesinizi test edip sonuçlarını elde etmiş olursunuz. Yüzde yüz birleşme olasılığı çok düşüktür, fakat %80 civarında bir tanıma da yabana atılacak bir sonuç değildir.
Ses Tanıma Sistemlerinde Karşılaşılan Sorunlar
Ses tanımanın belirli bir prosedürü olduğundan yukarıda bahsettim. Peki bu her şeyi çözüyor mu? Kısmen, evet. Fakat tanıtılması gereken sözcük sayısı ve sözdizimi karmaşıklığı arttıkça, tanıma yüzdesi de düşüyor. Bunun sebepleri ise söyle sıralanabilir:
- İngilizce'deki gibi yazılışları ve anlamları farklı olup okunuşları aynı olan sözcüklerin aynı cümlede kullanılması, makinenin konuşmayı çözümlerken doğru sonuç bulmasını engelleyebilir:_“Mr. Wright should write to Ms. Wright right away about his Ford or four door Honda.”_ cümlesindeki altı çizili sözcükler bu duruma örnek olarak verilebilir.
- Ses tanımanın birden fazla türü vardır. Yalıtılmış sözcük tanıma, sürekli sözcük tanımadan daha kolaydır. Çünkü ilkinde sözcükler nispeten daha açık ve tane tane söylenir. Aynı şekilde karşılıklı bir konuşmayla, okumadaki konuşma arasında da büyük fark vardır. Konuşma birinde sürekli ve değişken tonlamalarla, doğaçlama olarak gerçekleşirken, diğerinde tonlamalara dikkat edilerek, daha yavaş tempodadır.
- Konuşmacıya bağımlı ve konuşmacıdan bağımsız ses tanıma sistemlerinde de farklı performanslar sergilenir. Birden fazla konuşmacının sesini tanıyabilmek makinenin hesaplamalarını etkileyebilir.
- Konuşma sırasında fondaki gürültü düzeyi de önemli bir zorluk çıkarıcı etmendir.
Teknolojideki büyümenin önüne set çekmek mümkün değilken, ses tanımanın da gelişme hızı aynı şekilde artmakta. Ses tanımadaki zorlukların en büyük nedeni, bilgisayarın iç yapısındaki gibi ya 1 ya da 0 şeklinde yürümemesi. Temelinde kullanılan pek çok istatistiksel ve matematiksel formüllerin de gösterdiği gibi, olasılıklar ve yaklaşıklıklar üzerine kurulu bir sistem. Bu yüzden daha fazla Ar-Ge yapılarak, üzerinde sabırla ve titizlikle durulması gereken, fakat bir o kadar da ilginç bir konu ses tanıma. Umarım bir miktar olsun fikir sahibi yapabilmişimdir sizleri. Görüşmek üzere.